Drop columns in pandas DataFrame#
Datasets could be in any shape and form. To optimize the data analysis, we need to remove some data that is redundant or not required. This article aims to discuss all the cases of dropping single or multiple columns from a Pandas DataFrame.
The following functions are discussed in this article in detail:
df.drop(columns = ['col1','col2'...])df.pop('col_name')del df['col_name']
In the last section, we have shown the comparison of these functions. So stay tuned…
Also, See:
The DataFrame.drop() function#
We can use this pandas function to remove the columns or rows from simple as well as multi-index DataFrame.
Syntax:
DataFrame.drop(labels=None, axis=1, columns=None, level=None, inplace=False, errors='raise')
Parameters:
labels: It takes a list of column labels to drop.axis: It specifies to drop columns or rows. Set aaxisto 1 or columns to drop columns. By default, it drops the rows from DataFrame.columns: It is an alternative toaxis='columns'. It takes a single column label or list of column labels as input.level: It is used in the case of a MultiIndex DataFrame to specify the level from which the labels should be removed. It takes a level position or level name as input.inplace: It is used to specify whether to return a new DataFrame or update an existing one. It is a boolean flag with defaultFalse.errors: It is used to suppressKeyErrorerror if a column is not present. It takes the following 1. inputs:ignore: It suppresses the error and drops only existing labels.raise: Throws the errors if the column does not exist. It is the default case.
Returns:
It returns the DataFrame with dropped columns or None if
inplace=TrueIt also raises
KeyErrorif labels are not found.
Drop single column#
We may need to delete a single or specific column from a DataFrame.
In the below example we drop the age column from the DataFrame using df.drop(columns = 'col_name')
import pandas as pd
student_dict = {"name": ["Joe", "Nat"], "age": [20, 21], "marks": [85.10, 77.80]}
# Create DataFrame from dict
student_df = pd.DataFrame(student_dict)
print(student_df)
# drop column
student_df = student_df.drop(columns='age')
print(student_df)
name age marks
0 Joe 20 85.1
1 Nat 21 77.8
name marks
0 Joe 85.1
1 Nat 77.8
Drop multiple columns#
Use any of the following two parameters of DataFrame.drop() to delete multiple columns of DataFrame at once.
Use the
columnparameter and pass the list of column names you want to remove.Set the
axis=1and pass the list of column names.
Example:
Let’s see how to drop multiple columns from the DataFrame.
import pandas as pd
student_dict = {"name": ["Joe", "Nat"], "age": [20, 21], "marks": [85.10, 77.80]}
student_df = pd.DataFrame(student_dict)
print(student_df.columns.values)
# drop 2 columns at a time
student_df = student_df.drop(columns=['age', 'marks'])
print(student_df.columns.values)
['name' 'age' 'marks']
['name']
Using drop with axis='columns' or axis=1#
Let’s see how to drop using the axis-style convention. This is a new approach. (This approach makes this method match the rest of the pandas API) .
Use the axis parameter of a DataFrame.drop() to delete columns. The axis can be a row or column. The column axis represented as 1 or ‘columns’.
Set axis=1 or axis='columns' and pass the list of column names you want to remove…
Example
Let’s see how to drop age and marks columns.
import pandas as pd
student_dict = {"name": ["Joe", "Nat"], "age": [20, 21], "marks": [85.10, 77.80]}
# Create DataFrame from dict
student_df = pd.DataFrame(student_dict)
print("Original dataframe:\n",student_df)
student_df = student_df.drop(['age', 'marks'], axis='columns')
print("After droping columns in dataframe:\n", student_df)
# alternative both produces same result
#student_df = student_df.drop(['age', 'marks'], axis=1)
#print("After droping columns in dataframe:\n", student_df)
Original dataframe:
name age marks
0 Joe 20 85.1
1 Nat 21 77.8
After droping columns in dataframe:
name
0 Joe
1 Nat
Drop column in place#
In the above examples, whenever we executed drop operations, pandas created a new copy of DataFrame because the modification is not in place.
Parameter inplace is used to indicate if drop column from the existing DataFrame or create a copy of it.
If the
inplace=Truethen it updates the existing DataFrame and does not return anything.If the
inplace=Falsethen it creates a new DataFrame with updated changes and returns it.
Note: Set
inplace=Truewhen we are doing function chaining to avoid assigning the result back to a variable as we are performing modifications in place.
import pandas as pd
student_dict = {"name": ["Joe", "Nat"], "age": [20, 21], "marks": [85.10, 77.80]}
student_df = pd.DataFrame(student_dict)
print(student_df.columns.values)
# drop columns in place
student_df.drop(columns=['age', 'marks'], inplace=True)
print(student_df.columns.values)
['name' 'age' 'marks']
['name']
Drop column by suppressing errors#
By default, The DataFrame.drop() throws KeyError if the column you are trying to delete does not exist in the dataset.
If we want to drop the column only if exists then we can suppress the error by using the parameter errors.
Set
errors='ignore'to not throw any errors.Set
errors='raised'to throwKeyErrorfor the unknown columns
Example:
In the below example, we are trying to drop the column which does not exist in the DataFrame.
import pandas as pd
student_dict = {"name": ["Joe", "Nat"], "age": [20, 21], "marks": [85.10, 77.80]}
# Create DataFrame from dict
student_df = pd.DataFrame(student_dict)
print(student_df)
# supress error
student_df = student_df.drop(columns='salary', errors='ignore') # No change in the student_df
# raise error
student_df = student_df.drop(columns='salary') # KeyError: "['salary'] not found in axis"
name age marks
0 Joe 20 85.1
1 Nat 21 77.8
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-5-245426098662> in <module>
11
12 # raise error
---> 13 student_df = student_df.drop(columns='salary') # KeyError: "['salary'] not found in axis"
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\frame.py in drop(self, labels, axis, index, columns, level, inplace, errors)
4306 weight 1.0 0.8
4307 """
-> 4308 return super().drop(
4309 labels=labels,
4310 axis=axis,
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\generic.py in drop(self, labels, axis, index, columns, level, inplace, errors)
4151 for axis, labels in axes.items():
4152 if labels is not None:
-> 4153 obj = obj._drop_axis(labels, axis, level=level, errors=errors)
4154
4155 if inplace:
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\generic.py in _drop_axis(self, labels, axis, level, errors)
4186 new_axis = axis.drop(labels, level=level, errors=errors)
4187 else:
-> 4188 new_axis = axis.drop(labels, errors=errors)
4189 result = self.reindex(**{axis_name: new_axis})
4190
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\indexes\base.py in drop(self, labels, errors)
5589 if mask.any():
5590 if errors != "ignore":
-> 5591 raise KeyError(f"{labels[mask]} not found in axis")
5592 indexer = indexer[~mask]
5593 return self.delete(indexer)
KeyError: "['salary'] not found in axis"
Drop column by index position#
If there is a case where we want to drop columns in the DataFrame, but we do not know the name of the columns still we can delete the column using its index position.
Note: Column index starts from 0 (zero) and it goes till the last column whose index value will be
len(df.columns)-1.
Drop the last column#
Assume you want to drop the first column or the last column of the DataFrame without using the column name.
In such cases, use the DataFrame.columns attribute to delete a column of the DataFrame based on its index position. Simply pass df.columns[index] to the columns parameter of the DataFrame.drop().
Example
In the below example, we are dropping the last column of the DataFrame using df.columns[last_index].
import pandas as pd
student_dict = {"name": ["Joe", "Nat"], "age": [20, 21], "marks": [85.10, 77.80]}
# Create DataFrame from dict
student_df = pd.DataFrame(student_dict)
print(student_df.columns.values)
# find position of the last column and drop
pos = len(student_df.columns) - 1
student_df = student_df.drop(columns=student_df.columns[pos])
print(student_df.columns.values)
# delete column present at index 1
# student_df.drop(columns = student_df.columns[1])
['name' 'age' 'marks']
['name' 'age']
Drop range of columns using iloc#
There could be a case when we need to delete the fourth column from the dataset or need to delete a range of columns. We can use DataFrame.iloc to select single or multiple columns from the DataFrame.
We can use DataFrame.iloc in the columns parameter to specify the index position of the columns which need to drop.
Example:
Let’s see how we can drop the range of the columns based on the index position. In the below example, we are dropping columns from index position 1 to 3 (exclusive).
import pandas as pd
student_dict = {"name": ["Joe", "Nat"], "age": [20, 21], "marks": [85.10, 77.80]}
# Create DataFrame from dict
student_df = pd.DataFrame(student_dict)
print(student_df.columns.values)
# drop column from 1 to 3
student_df = student_df.drop(columns=student_df.iloc[:, 1:3])
print(student_df.columns.values)
['name' 'age' 'marks']
['name']
Drop first n columns#
If we need to delete the first ‘n’ columns from a DataFrame, we can use DataFrame.iloc and the Python range() function to specify the columns’ range to be deleted.
We need to use the built-in function range() with columns parameter of DataFrame.drop().
Example:
In the below example, we are dropping the first two columns from a DataFrame.
import pandas as pd
student_dict = {"name": ["Joe", "Nat"], "age": [20, 21], "marks": [85.10, 77.80], "class": ["A", "B"],
"city": ["London", "Zurich"]}
# Create DataFrame from dict
student_df = pd.DataFrame(student_dict)
print("Before dropping: \n", student_df.columns.values)
# drop column 1 and 2
student_df = student_df.drop(columns=student_df.iloc[:, range(2)])
# print only columns
print("\nAfter dropping: \n", student_df.columns.values)
Before dropping:
['name' 'age' 'marks' 'class' 'city']
After dropping:
['marks' 'class' 'city']
Drop column from multi-index DataFrame#
DataFrame can have multiple column headers, such DataFrame is called a multi-index DataFrame. Such headers are divided into the levels where the first header is at level 0, the second header is at level 1, and so on.
We can drop a column from any level of multi-index DataFrame. By default, it drops columns from all the levels, but we can use a parameter level to drop from a particular level only.
We need to pass a level name or level index as level=level_index.
Below is the multi-index DataFrame with two column headers.
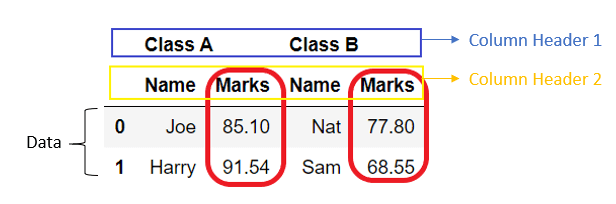
Example:
Let’s see how we can drop column marks from level 1.
Note: If we do not provide a
levelparameter then it will drop the column from all the levels if exist.
import pandas as pd
# create column header
col = pd.MultiIndex.from_arrays([['Class A', 'Class A', 'Class B', 'Class B'],
['Name', 'Marks', 'Name', 'Marks']])
# create dataframe from 2darray
student_df = pd.DataFrame([['Joe', '85.10', 'Nat', '77.80'], ['Harry', '91.54', 'Sam', '68.55']], columns=col)
print("Before dropping column: \n", student_df)
# drop column
student_df = student_df.drop(columns=['Marks'], level=1)
print("\nAfter dropping column: \n", student_df)
Before dropping column:
Class A Class B
Name Marks Name Marks
0 Joe 85.10 Nat 77.80
1 Harry 91.54 Sam 68.55
After dropping column:
Class A Class B
Name Name
0 Joe Nat
1 Harry Sam
Drop column using a function#
We can also use the function to delete columns by applying some logic or based on some condition. We can use built-in as well as user-defined functions to drop columns.
Drop all the columns using loc#
If we want to drop all the columns from DataFrame we can easily do that using DataFrame.loc in the columns parameter of DataFrame.drop().
DataFrame.loc is used to specify the column labels which need to delete. If we do not specify any column labels like df.loc[:] then it will drop all the columns in the DataFrame.
Example:
In the below example, we are dropping all the columns from the student DataFrame.
import pandas as pd
student_dict = {"name": ["Joe", "Nat"], "age": [20, 21], "marks": [85.10, 77.80]}
# Create DataFrame from dict
student_df = pd.DataFrame(student_dict)
print("Before dropping column: \n", student_df.columns.values)
# drop column 1 and 2
student_df = student_df.drop(columns=student_df.loc[:])
# print only columns
print("\nAfter dropping column: \n", student_df.columns.values)
Before dropping column:
['name' 'age' 'marks']
After dropping column:
[]
Drop column using pandas DataFrame.pop() function#
If we want to delete a single column then we can also do that using DataFrame.pop(col_label) function. We need to pass a column label that needs to delete.
It removes the column in-place by updating the existing DataFrame. It raises KeyError if the column is not found.
Note: It can be used to drop a column only. It cannot drop multiple columns or row(s).
Example:
Let’s see how we can drop the age column from a student DataFrame.
import pandas as pd
student_dict = {"name": ["Joe", "Nat"], "age": [20, 21], "marks": [85.10, 77.80]}
# Create DataFrame from dict
student_df = pd.DataFrame(student_dict)
print("Before dropping column: \n", student_df)
# drop column
student_df.pop('age')
print("\nAfter dropping column: \n", student_df)
Before dropping column:
name age marks
0 Joe 20 85.1
1 Nat 21 77.8
After dropping column:
name marks
0 Joe 85.1
1 Nat 77.8
Drop column using pandas DataFrame delete#
We can also use the pandas inbuilt function del to drop a single column from a DataFrame. It is a very simplified way of dropping the column from a DataFrame.
We need to select the column of DataFrame which needs to be deleted and pass it as del df[col_label].
Note: It can be used to drop a column only. It cannot drop multiple columns or row(s).
import pandas as pd
student_dict = {"name": ["Joe", "Nat"], "age": [20, 21], "marks": [85.10, 77.80]}
# Create DataFrame from dict
student_df = pd.DataFrame(student_dict)
print("Before dropping column: \n", student_df)
# drop column
del student_df['age']
print("\nAfter dropping column: \n", student_df)
Before dropping column:
name age marks
0 Joe 20 85.1
1 Nat 21 77.8
After dropping column:
name marks
0 Joe 85.1
1 Nat 77.8
Compare DataFrame drop() vs. pop() vs. del#
Features |
|
|
|
|---|---|---|---|
Operates on axis |
columns and rows |
only column |
only column |
Delete multiple columns |
Yes |
No |
No |
Drop in-place or return a copy |
Both |
Only in-place |
Only in-place |
Performance |
Fast |
Slow |
Slow |