Time Series & LV Plot#
Welcome back to another lecture on Data Visualization with Seaborn. We have already consumed a heavy chunk of required information to draft a plot for any kind of data that comes our way. We have rigorously gone through every possible Regression plot as well as plot for Categorical variables. Time and again, we have looked into the statistical inference that can be drawn from our graphs; and tried to achieve more & more by customizing it using underlying Matplotlib code and style.
Overall if at this stage, someone asks us to draw a plot just based off Matplotlib, I am sure you guys will be able to do that as well, though ofcourse that isn’t our agenda in this course. Though I promised in the last lecture to cover “Time Series Plot” this time, but I have planned to share something more than that. So, we will be covering Time-Series plot, but additionally, we shall be looking into one more handy way of handling Regression using Seaborn.
As we already have previously done, extensive detailing for Regression, we shall in fact start this lecture today with this additional topic. This particular plot for Regression that we’re going to cover is known as “Letter Value Plot”, also commonly known as LV Plot.
Letter Value (LV) Plot#
As always, let us begin by understanding what this plot is and how can it be helpful for us; before we dig deeper into plotting these with some data. So, Letter value (LV) plots are non-parametric estimates of the distribution of a dataset, quite similar to Box Plot. LV plots are also pretty similar to Violin plots but excluding the need to fit a Kernel Density estimate. Thus, LV plots are fast to generate, directly interpretable in terms of the distribution of data, and easy to understand.
In Statistical modelling, the general idea of non-parametric estimation is to use the past information that most closely resembles the present, without establishing any concrete prediction model. Suppose we need to predict future returns of a series, that contains enough information in it’s prior data to predict the next value, but we don’t know how much information out of this dataset is non-disposable for prediction; and till what time-stamp should we go back and use this data. There is always a risk of over-fitting as well.
This is where, non-parametric estimation comes in handy with a smooting window parameter that provide bands around our set of observations in a series with autoregression. We focus on the value that follows each block (where each block has a fixed set of observations previous to today as per autoregression order) and compute weighted average. More similar these blocks, more weight is allocated to next observation. By the way, these weights are determined with our smoothing function (also termed as kernel); and there are multiple smoothing functions to choose from like Uniform, Gaussian, Dirichlet, etc. (though the most common one is Gaussian).
My sole purpose of taking you through such statistical background of each plot and related concepts, is just to ensure that if someday, a fine gentleman in an interview tries to test your knowledge beyond your programming/coding skills, you should be able to answer at least upto an extent, even if you don’t have a Stats background. Honestly, even if you could just mention the keywords, it kind of assures an interviewer or a manager, that they have assigned their task to someone who knows what they’re doing.
Let us now plot a simple LV Plot and then try to find out if we have any optional parameter available that we haven’t encountered till now (although that shouldn’t be the case). So let us begin by quickly importing our dependencies and setting the aesthetics for future use:
# Importing intrinsic libraries:
import numpy as np
import pandas as pd
np.random.seed(44)
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set(style="darkgrid", palette="rainbow")
import warnings
warnings.filterwarnings("ignore")
# Let us also get tableau colors we defined earlier:
tableau_20 = [(31, 119, 180), (174, 199, 232), (255, 127, 14), (255, 187, 120),
(44, 160, 44), (152, 223, 138), (214, 39, 40), (255, 152, 150),
(148, 103, 189), (197, 176, 213), (140, 86, 75), (196, 156, 148),
(227, 119, 194), (247, 182, 210), (127, 127, 127), (199, 199, 199),
(188, 189, 34), (219, 219, 141), (23, 190, 207), (158, 218, 229)]
# Scaling above RGB values to [0, 1] range, which is Matplotlib acceptable format:
for i in range(len(tableau_20)):
r, g, b = tableau_20[i]
tableau_20[i] = (r / 255., g / 255., b / 255.)
# Loading built-in Tips dataset:
titanic = sns.load_dataset("titanic")
# Setting Plot size and font style:
plt.rcParams['figure.figsize'] = (12.0, 8.0)
plt.rcParams['font.family'] = "serif"
# Plotting a basic LV Plot:
sns.boxenplot(x="class", y="fare", hue="sex", data=titanic, palette="rocket")
sns.catplot(x="class", y="fare", hue="sex", data=titanic, palette="rocket", kind="boxen")
<seaborn.axisgrid.FacetGrid at 0x1edcdfafd30>
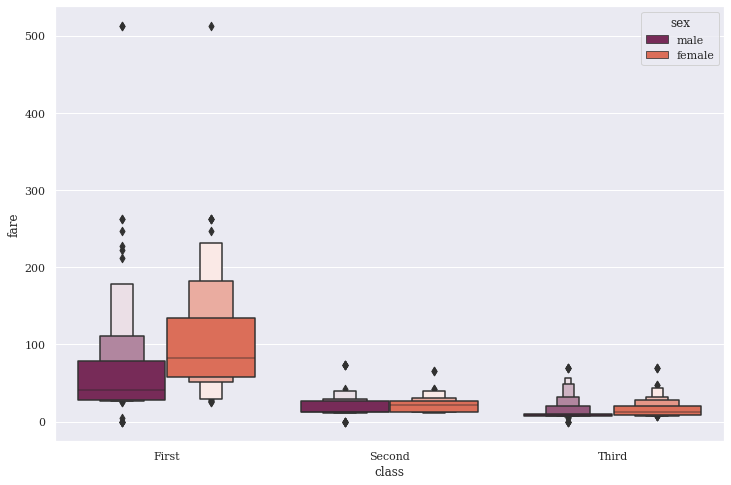
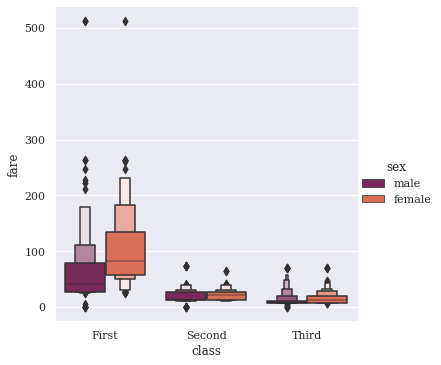
This beauty looks quite similar to Box plot, but more closely follow the principles, that governed John Wilder Tukey’s conventional boxplot. A good to know fact, John Tukey was the founding chairman of the Princeton statistics department and had been decorated with numerous awards and honors. His original Box plot in 1977 did wonders with small-sized datasets, conveying rough information about the central 50% and the extent of data. I shall also attach link to an information-rich paper by Hadley & Karen about their study on LV Plots.
As we notice in our plot, the whiskers from Box plot have been replaced with a variable number of letter values, selected solely based on the uncertainty associated with each non-parametric estimate and hence on the number of observations. Any values outside the most extreme letter value are displayed individually. These two modifications reduce the number of “outliers” displayed for large data sets, and make letter-value plots extremely useful over a much wider range of data sizes. But they also remain true to the spirit of boxplots by displaying only actual observations from the data sample, thus remaining free of tuning parameters. I am sure you can observe these skewed tails.
Let me plot this one another dataset, though the datasets that we are using aren’t really huge, but shall still give us a fair idea of distribution:
# Loading built-in Tips dataset:
tips = sns.load_dataset("tips")
sns.boxenplot(x="day", y="total_bill", hue="smoker", data=tips, palette="plasma")
<AxesSubplot:xlabel='day', ylabel='total_bill'>
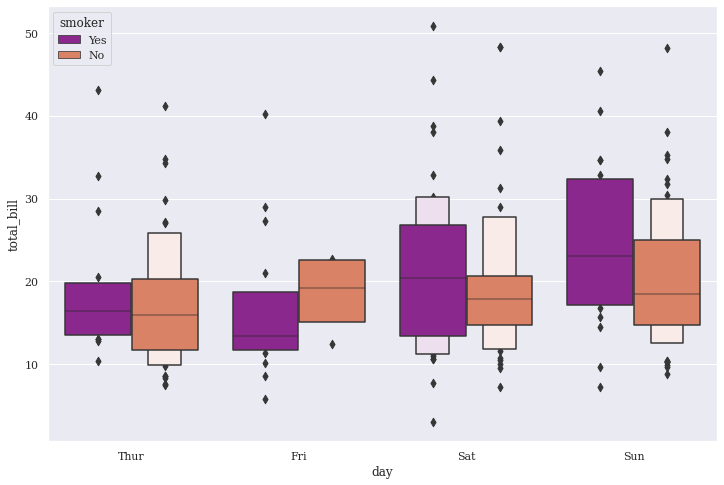
Tips dataset seems to show much better distribution than Titanic so let us stick to this. We do notice that as the data chunk keeps changing, the boxes accordingly represent the distribution. Also, the outliers have been limited at the end of each tail for respective days, thus displaying only those Total bill values that have approximately 95% Confidence Intervals, and do not overlap the successive letter values.
Let us now run through the parameters offered by Seaborn:
seaborn.lvplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, width=0.8, dodge=True, k_depth='proportion', linewidth=None, scale='exponential', outlier_prop=None, ax=None)
Nice! So apart from regular params, we have three new optional parameters offered by Seaborn team to help us visualize data better: We have:
k_depththat indicates number of boxes, and by extension number of percentiles, to draw. Here, each box makes different assumptions about the number of outliers and leverages different statistical properties. The paper by Hadley & Karen that I mentioned earlier details available options. By default, Seaborn sets it toproportion, whereas we may also switch to conventionaltukeyandtrustworthy.Secondly we have
scaleparameter that decides the method to use for width of the letter value boxes, though all of them visually give similar results. By default it is set toexponentialwhere our plot uses the proportion of data not covered. Alternatively, we may chooselinearto reduce width by a constant linear factor; or selectarea, being proportional to the percentage of data covered.Finally we have
outlier_propthat is used in conjuction withk_depthparameter, thus representing proportion of data believed to be Outliers. Ideally, it defaults to0.007as a proportion of Outliers.
Time to observe how these optional parameters can create a difference in our plots so let us start by adding them one by one:
sns.boxenplot(x="day", y="total_bill", hue="smoker", data=tips, palette="icefire", k_depth="tukey", outlier_prop=0.007)
<AxesSubplot:xlabel='day', ylabel='total_bill'>
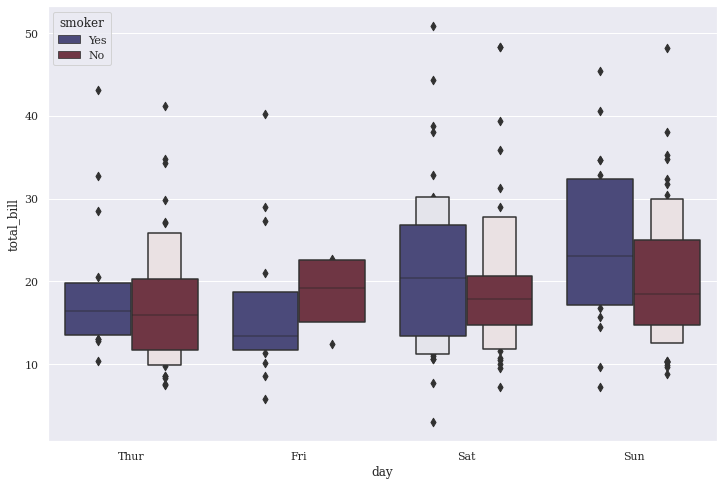
A lot changed in our plot by adding those parameters so let us infer what actually made a difference and how. We still have same data points with Total Bill being generated by customers on respective days, that gets further segregated by their Smoking habit. But now we have fewer boxes representing our data in a much generalized manner because Tukey method isn’t able to make ample assumptions with blocks of data points being passed on to it. In turn, even the count of Outliers being displayed increase. This vividly concretes our opinion on Tukey principles not being efficient on larger datasets, because Tips dataset certainly has over 200+ records.
Let us try to scale it now and see if that makes a difference. Simultaneously, we shall also try to redefine our Outlier proportion to a lower value:
# Trying to linearly adjust box width:
sns.boxenplot(x="day", y="total_bill", hue="smoker", data=tips, palette="icefire", k_depth="tukey",
scale="linear", outlier_prop=0.010)
<AxesSubplot:xlabel='day', ylabel='total_bill'>
Tukey principles just don’t seem to be working well for us, so let us give a last shot with trustworthy param:
#sns.lvplot(x="day", y="total_bill", hue="smoker", data=tips, palette="icefire", k_depth="trustworthy",
#scale="linear", outlier_prop=0.005)
# Final shot with defaults:
sns.boxenplot(x="day", y="total_bill", hue="smoker", data=tips, palette="icefire", scale="linear", outlier_prop=0.005)
<AxesSubplot:xlabel='day', ylabel='total_bill'>
Default parameter here, seems to fetch us what we really wanted, i.e. distributions plotted with boxes as per spike in total_bill. My primary agenda was just to play around with parameters to show you distribution disparity aesthetically with each parameter variation. Now, let us also try mixing our LV Plot with some other plot:
sns.boxenplot(x="day", y="total_bill", data=tips, palette="rocket")
sns.stripplot(x="day", y="total_bill", data=tips, size=6, jitter=True, color=tableau_20[1])
<AxesSubplot:xlabel='day', ylabel='total_bill'>
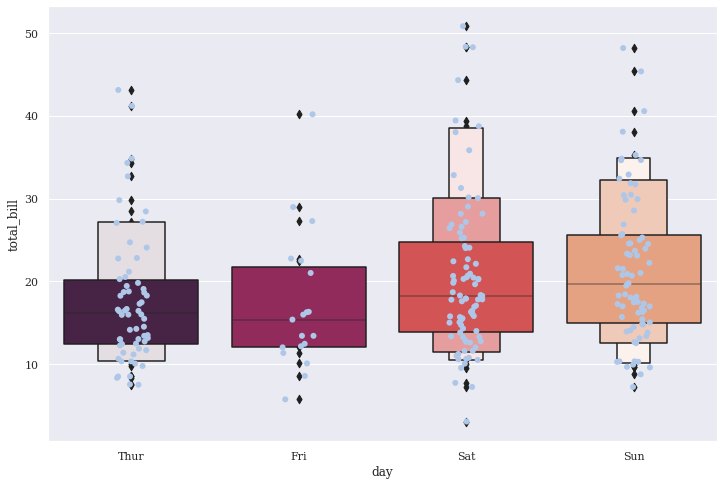
This combination looks pretty good. Generally, Strip plots are very well suited for such mixing to make our visualizations information-rich.
Sticking to our routine, now we should get our Letter Value plot further subdivided into sub-plots:
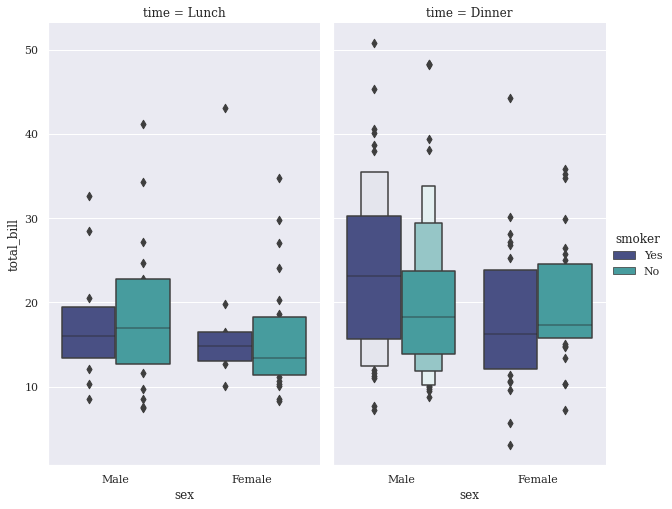
sns.factorplot(x="sex", y="total_bill", hue="smoker", col="time", data=tips, palette ="mako", kind="boxen", size=7, aspect=.6);
Time-Series Plot#
Please do remember that Letter Value plot takes all the data into consideration while plotting, so in general use if you don’t want that, it is better to stick with LM Plot or Reg Plot, that we discussed in previous section. Or else, if you want to take a custom track, you would have to reinvent the wheel by creating Custom PatchCollection yourself. Moving on, finally we have our topic of interest, i.e. “Time-Series Plot”.
So, a Time series is a series of data points that are indexed (or even listed or graphed) in order of time intervals. Most commonly, a time series is a sequence, taken at successive, equally spaced intervals in time. Thus, it is observed to be a sequence of discrete-time data. Very often, Time series data is plotted via Line Charts, and is commonly used in statistical domain, along with any other domain of Applied science and engineering which involves Temporal measurements.
In case you unaware, Temporal measurements, that are also commonly known as Chronometry takes 2 distinct period forms for computation:
One being Calendar, that is a mathematical abstraction for calculating extensive periods of time.
Other being Clock, that is a concrete mechanism to count the ongoing passage of time.
Hence, Time series data have a natural temporal ordering that makes time series analysis distinct from cross-sectional studies. Like: Explaining Employee wages by reference to their respective Education level, where an individuals’ data could be entered in any order. Time Series Analysis is also distinct from Spatial Data Analysis where the observations typically relate to geographical locations. Like: Estimating house prices by it’s Location, and other intrinsic characteristics of those houses.
A Stochastic model for a Time series will generally reflect the fact that observations close together in time, will be more closely related, than observations further apart. Additionally, Time series models often make use of the natural one-way ordering of time so that values for a given period will be expressed as a derivation from past values, rather than from future values.
The most common Temporal Visualization that you see almost every other day in real world could be something like:
An organization’s Sales growth in the last few quarters, or
Graphs showing a country’s GDP growth trends, etc.
We have already learnt few of the best ways to present such data using Seaborn, like:
Line Graph/Chart/Plot
Grouped Bar Plot, and even,
Stacked Horizontal Bar Plot
Today we’re going to add an important weapon to our arsenal for dealing with Temporal Measurements with the latest offering from Seaborn, namely Time Series Plot, or commonly known as just TS Plot. So, let us quickly get our Python package dependencies and then to begin with, we shall plot a simple Time Series data, adapting directly from Seaborn official:
# Importing intrinsic libraries:
import numpy as np
import pandas as pd
np.random.seed(41)
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set(style="darkgrid", palette="rocket")
import warnings
warnings.filterwarnings("ignore")
# Let us also get tableau colors we defined earlier:
tableau_20 = [(31, 119, 180), (174, 199, 232), (255, 127, 14), (255, 187, 120),
(44, 160, 44), (152, 223, 138), (214, 39, 40), (255, 152, 150),
(148, 103, 189), (197, 176, 213), (140, 86, 75), (196, 156, 148),
(227, 119, 194), (247, 182, 210), (127, 127, 127), (199, 199, 199),
(188, 189, 34), (219, 219, 141), (23, 190, 207), (158, 218, 229)]
# Scaling above RGB values to [0, 1] range, which is Matplotlib acceptable format:
for i in range(len(tableau_20)):
r, g, b = tableau_20[i]
tableau_20[i] = (r / 255., g / 255., b / 255.)
Let us now try to replicate official lineplot plot:
# Using Matplotlib to set figure size and Font style for our plot:
plt.rcParams['figure.figsize'] = (13.0, 8.0)
plt.rcParams['font.family'] = "serif"
# Declaring a linearly spaced variable with NumPy:
x = np.linspace(0, 15, 31)
# Creating linearly spaced dataset using our variable:
data = np.sin(x) + np.random.rand(10, 31) + np.random.randn(10, 1)
print(data)
fmri = sns.load_dataset("fmri")
sns.relplot(x="timepoint", y="signal", kind="line", data=fmri);
# Creating Time-Series plot:
ax = sns.relplot(data=data, kind="line", ci="sd")
# Labelling Axes:
ax.set_ylabel("Random Fluctuations")
ax.set_xlabel("Time Interval")
https://seaborn.pydata.org/generated/seaborn.lineplot.html#seaborn.lineplot
https://seaborn.pydata.org/tutorial/relational.html#relational-tutorial
[[ 9.05233094e-01 9.49890664e-01 1.96671753e+00 1.91703708e+00
2.18644463e+00 1.41083552e+00 1.25490048e+00 6.33094796e-01
2.68747069e-01 1.33114510e-01 -1.76093000e-01 4.60818266e-01
4.83319662e-01 1.33516842e+00 1.69361323e+00 1.34435993e+00
2.20784702e+00 1.37380679e+00 1.03068156e+00 5.97305419e-01
-1.61440440e-01 2.93082264e-01 -4.40904134e-01 -2.05473060e-01
6.69001671e-01 9.13409426e-01 1.36938945e+00 1.86299475e+00
1.31701798e+00 2.02683718e+00 1.21855997e+00]
[ 2.62242956e+00 2.37181743e+00 3.24813498e+00 3.53341062e+00
3.28254475e+00 3.17951135e+00 2.21741122e+00 1.45103300e+00
1.84254180e+00 1.30378713e+00 1.62503489e+00 1.03348578e+00
2.31708111e+00 2.65596512e+00 2.63465586e+00 2.87853325e+00
3.36782780e+00 2.70805473e+00 2.74304829e+00 2.17041474e+00
1.45409876e+00 1.79270929e+00 8.11421774e-01 1.54902750e+00
1.49798680e+00 2.22931538e+00 2.41292267e+00 2.96238081e+00
3.58099293e+00 2.63033250e+00 2.98514058e+00]
[ 5.79671774e-01 5.26568259e-01 8.46075265e-01 1.01710843e+00
1.53590397e+00 5.48013283e-01 4.14577043e-01 -1.31390556e-01
-9.35731444e-01 -1.00856914e+00 -7.60683359e-01 -7.22592182e-01
-2.24299133e-01 9.06947804e-01 1.29431485e+00 8.02989209e-01
1.44666284e+00 1.49529338e+00 8.00357518e-01 -5.44794755e-02
-4.19305918e-01 -1.65575249e-01 -5.36492380e-01 -8.13960670e-01
4.68603251e-02 -3.02919730e-01 8.42538101e-01 1.00140327e+00
1.00826323e+00 1.04617067e+00 9.56580759e-01]
[ 2.15514180e+00 3.00121062e+00 2.69736459e+00 3.48383283e+00
3.55965906e+00 3.01919923e+00 2.69272794e+00 1.72765023e+00
1.97187673e+00 1.36699927e+00 1.58662330e+00 1.38568225e+00
2.20800138e+00 2.82974801e+00 2.77678046e+00 3.38224839e+00
3.74400348e+00 3.28883356e+00 2.67526014e+00 1.95501935e+00
2.18089902e+00 1.68671849e+00 1.01345985e+00 1.55382448e+00
1.89380846e+00 2.54510477e+00 2.22709318e+00 3.10696289e+00
3.43196619e+00 3.13680419e+00 2.78883111e+00]
[ 5.01183409e-01 1.33205527e+00 1.09790012e+00 1.83098322e+00
1.39119225e+00 1.72352380e+00 1.06161913e+00 5.63212579e-01
-1.64387910e-02 -3.60332219e-03 -3.88165065e-01 3.67761063e-02
1.68334519e-01 7.05669558e-01 1.74098031e+00 1.58556641e+00
1.78993856e+00 1.74486871e+00 1.13915538e+00 9.11734513e-01
3.31002414e-01 2.20994144e-01 -5.72888392e-01 3.29560668e-01
5.59371929e-01 6.87786341e-01 1.25231985e+00 1.33662976e+00
2.11289431e+00 1.38787858e+00 1.75665366e+00]
[-4.83727878e-01 5.18324209e-01 3.72964213e-01 8.53360752e-01
4.85051737e-01 1.08309749e+00 -9.79018354e-02 -2.51601397e-01
-3.37144872e-01 -7.59362951e-01 -1.02539500e+00 -4.74149939e-01
-2.08333022e-01 6.87646883e-01 8.82636160e-01 1.27216990e+00
6.15687723e-01 9.82647438e-01 4.39764517e-01 -7.00960206e-02
-8.23611012e-01 -5.56348096e-01 -6.50628105e-01 -8.53783010e-01
-4.35994688e-01 -1.41406033e-01 5.30911403e-01 9.83847501e-01
8.24674836e-01 1.42499377e+00 5.56650192e-01]
[-4.39169378e-01 1.41405704e-01 6.74509907e-01 7.97739775e-01
1.31287314e+00 1.01051775e+00 3.90328251e-01 -7.98237187e-02
-6.49332966e-01 -9.02928161e-01 -1.38575866e+00 -4.11818328e-01
-3.91348997e-01 8.93054890e-02 7.69258130e-01 9.21260800e-01
7.07450952e-01 4.57330710e-01 -6.72223991e-02 -8.72247358e-02
-1.03387531e-01 -1.14847551e+00 -5.62996541e-01 -1.33768743e+00
-9.85956433e-01 -2.32105794e-01 1.69901020e-01 6.97087710e-01
1.21379529e+00 9.59621339e-01 7.78673234e-01]
[-2.05017144e+00 -1.47016730e+00 -6.79998373e-01 -8.99714633e-01
-4.99262966e-01 -1.04702762e+00 -1.75209323e+00 -1.71755233e+00
-1.83161031e+00 -2.74371246e+00 -2.19566591e+00 -2.38429280e+00
-1.70166723e+00 -1.22722896e+00 -7.22291790e-01 -8.80966303e-01
-9.57292499e-01 -9.60811794e-01 -1.39957927e+00 -1.90264482e+00
-1.87970769e+00 -2.20843398e+00 -2.26571389e+00 -2.50547116e+00
-1.71671100e+00 -1.97964329e+00 -1.12872044e+00 -6.19692239e-01
-4.41276190e-01 -4.37796264e-01 -5.21987980e-01]
[ 2.14183273e+00 2.06663512e+00 2.06563599e+00 2.65903086e+00
2.83288998e+00 1.83464298e+00 2.27891384e+00 1.22397933e+00
4.71432477e-01 4.72708198e-01 1.19789154e+00 7.74307119e-01
1.67631096e+00 2.01032310e+00 2.00778181e+00 2.20240789e+00
2.96139878e+00 2.40636423e+00 1.72638167e+00 1.48755100e+00
1.07659773e+00 1.10026431e+00 7.49769501e-01 7.62792336e-01
1.28675168e+00 1.90093797e+00 1.73712819e+00 2.82701252e+00
2.61675899e+00 2.14613738e+00 2.35488217e+00]
[ 1.58899709e+00 1.47320909e+00 2.09708521e+00 1.87285499e+00
2.64034418e+00 2.13914421e+00 1.49690158e+00 1.22417715e+00
8.33856867e-01 5.46063092e-01 -1.17137357e-02 4.48122198e-01
7.21748794e-01 1.24271445e+00 1.90891100e+00 2.30119580e+00
2.62311335e+00 1.84915141e+00 1.61670566e+00 1.31576734e+00
5.39594634e-01 9.53901780e-02 1.19735756e-01 5.57367853e-01
9.56077258e-01 1.53037048e+00 1.45468093e+00 2.38385823e+00
2.44120621e+00 1.81945073e+00 1.55109787e+00]]
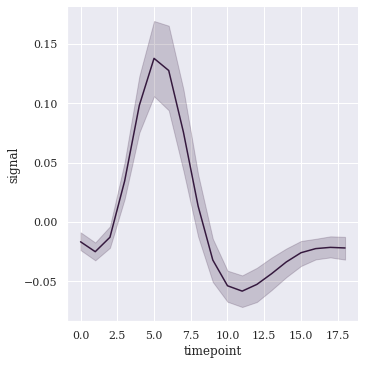
Let us first try to understand this random dataset before infering what the plot displays. So we begin by creating a linearly spaced variable x, where numpy.linspace() takes in the start, stop, and spacing parameter; and outputs a vector of 31 digits ranging from 0 to 15 at an interval of 0.5. Then to create our dataset, we use numpy.sin() from SciPy to create an element-wise array of trignometric sine values. And for further distortion, we use numpy.random.rand() to generate random samples between 0 and 1, as a uniform distribution. Once done creating dataset, we forward entire data to our Seaborn Lineplot Plot and what it displays is a trace with translucent confidence interval bands.
This Confidence Interval band of the mean depicts a range with an upper and lower number calculated from our dataset. Because the true population mean is unknown, this range describes possible values that the mean could be. If there had been multiple samples being drawn from the same population; and a 95% CI calculated for each sample, then we could expect the entire population mean to be found within 95% of these CIs. Always remember that these CIs are very sensitive to variability in the population (i.e. Spread of values) along with each sample size. I shall also attach a link in this notebook, if you want to study more on CIs.
Moving on, let us now check out the parameters available with Seaborn TS PLot for precision and customization. So the syntax looks like this:
seaborn.tsplot(data, time=None, unit=None, condition=None, value=None, err_style='ci_band', ci=68, interpolate=True, color=None, estimator=<function mean>, n_boot=5000, err_palette=None, err_kws=None, legend=True, ax=None)
Well it looks like we need to get acquainted with a lot of new parameters here so let us run through them one by one:
Topping our list of parameters is
time. This is used for the time-format variable from our dataset to get drafted on X-axis. In our example previously, we used NumPy random function to generate uniform values for our Time series.Next is
unitparameter which comes handy if we have enough data, as in more than just a vector, unlike what we had. This is a field in our dataset that identifies the Sampling unit. A Sampling unit is one of the units into which an aggregate is divided for the purpose of sampling, each unit being regarded as individual and indivisible, when sample selection is made.Then we have
condition, that is often used when we have a Series with a labels assigned, and thus for each label, a separate trace is plotted and accordingly forms our plot legend.We also have
err_stylethat we can relate to from our previous lecture, that has fixed set of options within Seaborn to choose from likeci_band,ci_bars, etc. to plot uncertainty acrossunits, corresponding toX-axis.This time our
ciis by default at68, but ofcourse we can modify this parameter.interpolatehelps us to do a Linear Interpolation between each timepoint and The value of this parameter also determines the marker used for the main plot traces (unlessmarkeris specified as a keyword argument).
Those are actually the commonly used params so let us now start plotting, and slowly we would get adjusted to rest of the required parameters as well.
# Importing another Built-in dataset:
gam = sns.load_dataset("gammas")
# Previewing Dataset:
gam.head(10)
| timepoint | ROI | subject | BOLD signal | |
|---|---|---|---|---|
| 0 | 0.0 | IPS | 0 | 0.513433 |
| 1 | 0.0 | IPS | 1 | -0.414368 |
| 2 | 0.0 | IPS | 2 | 0.214695 |
| 3 | 0.0 | IPS | 3 | 0.814809 |
| 4 | 0.0 | IPS | 4 | -0.894992 |
| 5 | 0.0 | IPS | 5 | -0.073709 |
| 6 | 0.0 | IPS | 6 | 3.542734 |
| 7 | 0.0 | IPS | 7 | 0.080169 |
| 8 | 0.0 | IPS | 8 | 1.547083 |
| 9 | 0.0 | IPS | 9 | 2.827153 |
Seaborn’s built-in gammas is just a fake compilation of raw magnetic resonance imaging (MRI) dataset which is freely available online. We don’t actually have to focus on data analysis part so let us instead try to get subject feature to our X-axis and accordingly plot BOLD signal datapoints on our y-axis.
gam = sns.load_dataset("gammas")
#sns.tsplot(time="timepoint", value="BOLD signal", unit="subject", condition="ROI", data=gam)
sns.lineplot(x="timepoint", y="BOLD signal", hue="ROI", units="subject", data=gam, estimator=None,lw=1,
);
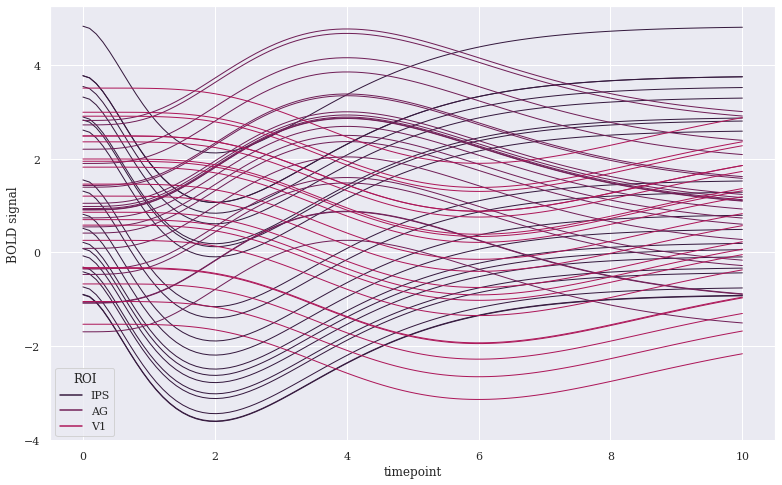
Here, the time component was picked from timepoint feature, hence labelled acordingly on X-axis. Separate traces using condition parameter have been plotted according to ROI feature of our Dataset, along with respective legends. If we don’t want Legend, we may remove it by adding legend=False. We could have also altered ci bandwidth color using any of the color options supported by Matplotlib, like our pre-defined tableau_20 colors. Let us use few more params:
# We're gonna use built-in 'data' again:
#sns.tsplot(data=data, err_style="ci_bars")
# Let us now remove interpolation between datapoints & select a range for our Confidence band:
sns.lineplot(data=data, err_style="bars", ci=[68], estimator=np.median)
<AxesSubplot:>
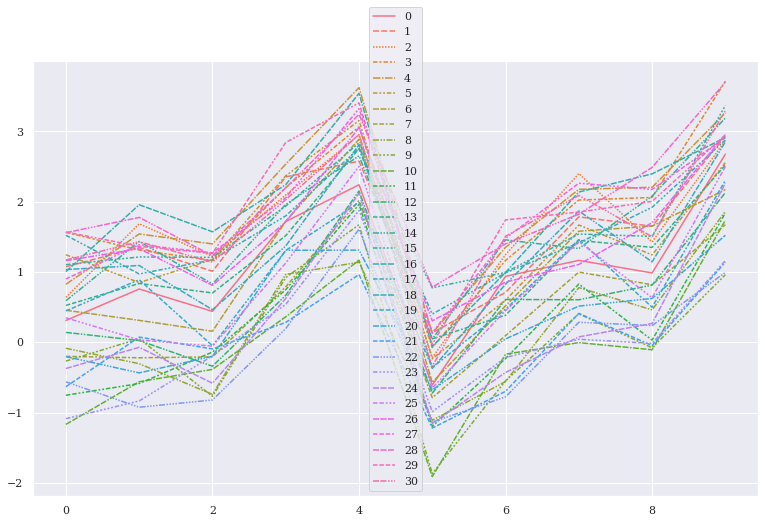
Let us now try to get each bootstrap resampling done:
sns.set(style="whitegrid", palette="icefire")
sns.tsplot(data=data, err_style="boot_traces", interpolate=False, estimator=np.median, n_boot=500)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-38-e8fb9ed4ccdc> in <module>
1 sns.set(style="whitegrid", palette="icefire")
2
----> 3 sns.tsplot(data=data, err_style="boot_traces", interpolate=False, estimator=np.median, n_boot=500)
AttributeError: module 'seaborn' has no attribute 'tsplot'
err_style parameter here gives us a pretty powerful tool for Bootstrapping, which is again a statistical technique that falls under the broader heading of Resampling. This technique involves a relatively simple procedure but repeated so many times that we require computers to compute, as visible in our plot with multiple separate traces. This Bootstrapping provides a method other than Confidence Intervals to estimate a population parameter. Let us try to plot with another modification to err_style which is our utmost critical parameter:
ax = sns.lineplot(data=data, err_style="band", estimator=np.median, n_boot=1000)
# Labelling Axes:
ax.set_ylabel("Bootstrap Iterations")
ax.set_xlabel("Time Interval")
Text(0.5, 0, 'Time Interval')
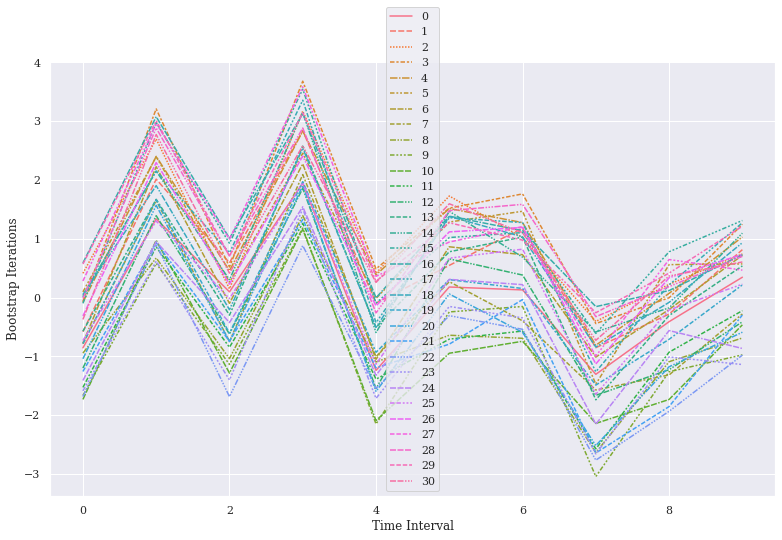
It is our n_boot parameter which is controlling the number of bootstrap operations here, thus showing trace from each sampling unit. We may add interpolate=False and the line shall become dotted to avoid representation as a Linear interpolation.
With Seaborn Time Series plot, you always need to be careful about the fact that the assumptions it makes about the Input data are that you’ve sampled the same units at each timepoint (although you can have missing timepoints for some units).
For example, say you measured blood pressure from the same group of people every day for a month, and now you want to plot average blood pressure by condition (where maybe the condition variable is the Type of diet they are on). tsplot could do this, with a call that would look something like
sns.tsplot(df, time="day", unit="person", condition="diet", value="blood_pressure")
But now, let me create a random DataFrame for you to help you understand on what type of dataset, TS Plot won’t be efficient for you.
With Seaborn Time Series plot, you always need to be careful about the fact that the assumptions it makes about the Input data are that you’ve sampled the same units at each timepoint (although you can have missing timepoints for some units).
For example, say you measured blood pressure from the same group of people every day for a month, and now you want to plot average blood pressure by condition (where maybe the condition variable is the Type of Diet they are on). tsplot could do this, with a call that would look something like
sns.tsplot(df, time="day", unit="person", condition="diet", value="blood_pressure")
But for large groups of people on different diets, and each day randomly sampling few people from segregated groups and measuring their blood pressure, TS Plot won’t be a great choice. In such scenarios, you would either require other ways mentioned earlier to plot using customizable options of Matplotlib.
And with that, we shall conclude our discussion on Time-Series and Letter-Value Plot. Ou next topic is going to be more specifically on Grids. Meanwhile today I am going to assign you a homework that you need to complete on your own. This assignment would majorly focus on the skills that you gained in today’s lecture.
I shall attach a dataset named “nyc_taxi.csv”, that is going to be in your Resources folder. This dataset is based on the 2016 NYC Yellow Cab trip record data, made available in Big Query on Google Cloud Platform. It was originally published by the NYC Taxi and Limousine Commission (TLC) and it’s cleansed form has been attached for you to work upon. At the end of this Lecture notebook, you shall find description of all the fields in this dataset. Also a link to original Google Big Query dataset has been also attached, just in case you wish to check.
id- a unique identifier for each tripvendor_id- a code indicating the provider associated with the trip recordpickup_datetime- date and time when the meter was engageddropoff_datetime- date and time when the meter was disengagedpassenger_count- the number of passengers in the vehicle (driver entered value)pickup_longitude- the longitude where the meter was engagedpickup_latitude- the latitude where the meter was engageddropoff_longitude- the longitude where the meter was disengageddropoff_latitude- the latitude where the meter was disengagedstore_and_fwd_flag- This flag indicates whether the trip record was held in vehicle memory before sending to the vendor because the vehicle did not have a connection to the server - Y=store and forward; N=not a store and forward triptrip_duration- duration of the trip in seconds
Finally at the bottom of your notebook is a LINK TO SOLUTION that you may use once you are done attempting. Please note that I am referecing to a workbook as an Exercise only for you to get some hands on practice visualizing real-time dataset. BUT that also means that it shall require some additional data wrangling skills that you will have to look into yourself.
In the next lecture, we shall learn to work with another type f grid, i.e Pair Grid.
Meanwhile keep playing around with all that we have learnt till date on sample datasets, and I shall see you in our next lecture on Grids.
Well with all of that been explained, I shall now take your leave and hope to see you guys in the next lecture. Till then, Happy Visualizing!